Other libraries of interest¶
Part of the following librairies address an incresingly common problem: what happens if the data we wish to analyze is “big data”?
We learned how to use Numpy, Pandas, and Xarray to analyze various types of environmental data. There are obviously many others useful libraries, especially when it comes to Big data.
Note
Big data is data sets that are so voluminous and complex that traditional data processing application software are inadequate to deal with them.
By this definition, most of the dataset we are regularly confronted to in environmental science (actually in Earth science more generally) are big data.
Faster array manipulation¶
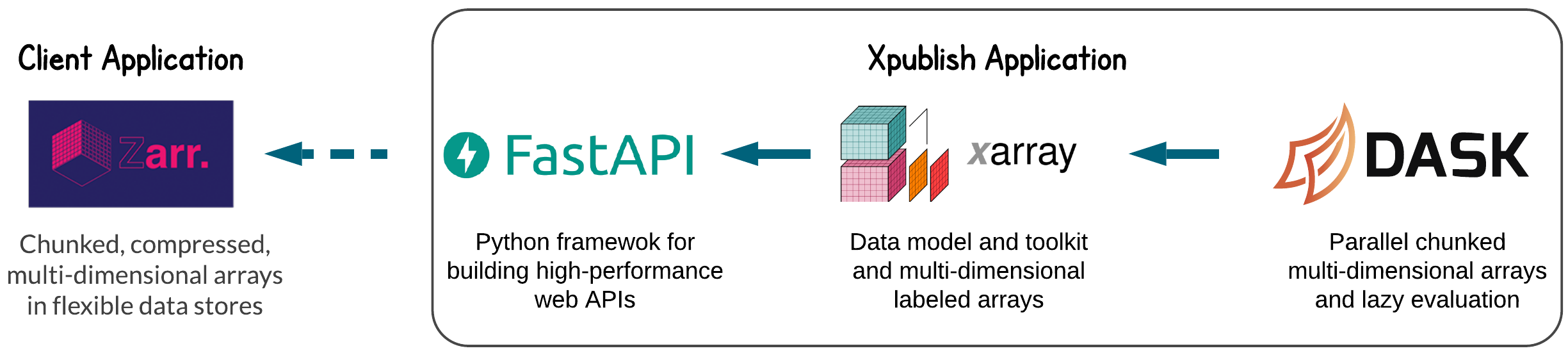
Data loading libraries¶
NCI examples¶

A useful overview of the National Computing Infrastructure data collection and services can be found here. Series of Jupyter notebooks examples are provided.
NCI Dask themed notebook tutorials demonstrate how to use Dask on data collections hosted at the NCI as well as data extracted from external databases (especially for eReefs models one can look at the following
Dask_13_intensive_calculation_eReef.ipynbnotebook).NCI THREDDS demonstrate how to access data stored on NCI’s THREDDS Data Server using Jupyter notebooks.